Goal
In You Need an LLM Router, I set up LiteLLM to unify access to models running across heterogeneous home lab hardware. That post defined the router’s functional aliases and a first-pass model assignment. What it didn’t do was prove those assignments were correct.
This post documents the benchmarking process that produced the final configuration: the right model on the right hardware for each workload class, with no model swapping, maximized resource utilisation, and the fastest possible response time for each use case.
The goal is simple: assign the best available open-source model to each workload class so that every request gets the fastest possible response, without evicting other resident models from memory.
Open-source models are released frequently. This process will need to be repeated — hence the date in the post title.
Hardware
I have four hosts available for inference:
| Host | Hardware | Memory | Notes |
|---|---|---|---|
star | Apple M3 Ultra | 96 GB unified | ~800 GB/s memory bandwidth |
cranberry | 2× Nvidia P40 | 48 GB VRAM total | Accessed via ollama (Traefik proxy) |
banana | Nvidia 4070Ti | 16 GB VRAM | CUDA; AMD GPUs occupied by other workloads |
clementine | Apple M4 Pro | 24 GB unified | OpenClaw gateway; also runs LiteLLM proxy |
Apple Silicon hosts share memory between CPU and GPU, with macOS reserving approximately 10–12 GB for the OS. CUDA hosts expose VRAM directly with minimal overhead (~2 GB on banana, negligible on cranberry’s P40s).
Memory Budgets
| Host | Usable for models | Constraint |
|---|---|---|
star | ~84 GB | One very large model, or carefully sized pairs |
cranberry | ~44 GB | Up to three mid-tier models simultaneously |
banana | ~14 GB VRAM | Two or three small models; nothing above ~10 GB loaded size |
clementine | ~20 GB | Light workload; gateway and failover role |
The constraint I designed everything around: all models assigned to a host must fit in memory simultaneously. When Ollama needs to load a model that doesn’t fit alongside what is already resident, it evicts the least-recently-used model. That eviction adds 30–60 seconds of cold-load latency to the affected request — and to the next request for the evicted model.
Defining the Workload Classes
Before touching any configuration, I defined the workloads the router actually needs to serve. Seven classes came out of the OpenClaw agent structure, Home Assistant integrations, and development tooling:
| Class | Alias | Description | Key Requirement |
|---|---|---|---|
| 1 | tools_fast | Structured extraction, JSON output, tool calls | Correctness over depth; low latency |
| 2 | reasoning_fast | Quick factual responses, short answers | Minimal latency |
| 3 | reasoning_slow | Analysis, comparison, mid-tier synthesis | Quality over speed; up to 90s acceptable |
| 4 | coding | Code generation with correct patterns | Coding-specialist model preferred |
| 5 | research | Deep synthesis, long-form output | Best available model; quality over speed |
| 6 | vision | Image understanding (text proxy for benchmarking) | Multimodal-capable model |
| 7 | embedding | Vector generation for RAG pipelines | Deterministic; latency-sensitive |
Each class needed a model matched to those requirements, hosted somewhere that fit within the memory budget without displacing other resident models.
The Test Framework
I built all the benchmarks on Python’s standard library — no external dependencies beyond the Ollama OpenAI-compatible API.
Shared Utilities (test_utils.py)
test_utils.py handles host resolution, model warm-up, API calls, and result formatting. The warm-up function is worth paying attention to: embedding models reject the /api/generate endpoint with HTTP 400, so I fall back to /v1/embeddings for those.
"""
Shared utilities for LLM benchmark scripts.
"""
import json
import time
import urllib.request
from datetime import datetime
KNOWN_HOSTS = {
"clementine": "http://clementine:11434",
"banana": "http://banana:11434",
"cranberry": "https://ollama",
"star": "http://star:11434",
}
def resolve_host(host: str) -> str:
"""Accept a short name (clementine, banana, cranberry, star) or a raw URL."""
if host in KNOWN_HOSTS:
return KNOWN_HOSTS[host]
if host.startswith("http"):
return host.rstrip("/")
return f"http://{host}"
def _post(url: str, body: dict, timeout: int = 300) -> dict:
data = json.dumps(body).encode()
req = urllib.request.Request(
url, data=data, headers={"Content-Type": "application/json"}
)
with urllib.request.urlopen(req, timeout=timeout) as resp:
return json.loads(resp.read())
def warm_model(base: str, model: str) -> None:
"""
Pre-load model into memory. Blocks until the model reports ready.
Uses /api/generate for chat models; falls back to /v1/embeddings for
embedding models (which reject /api/generate with HTTP 400).
"""
print(f"Warming up {model} on {base} ...", flush=True)
try:
_post(f"{base}/api/generate", {"model": model, "keep_alive": -1}, timeout=300)
except Exception as e:
if "400" in str(e):
# Embedding model — use the embeddings endpoint to load it
_post(f"{base}/v1/embeddings", {"model": model, "input": "warm"}, timeout=30)
else:
raise
print(f"Ready.", flush=True)
def run_chat(base: str, model: str, prompt: str, max_tokens: int = 8192) -> dict:
payload = {
"model": model,
"max_tokens": max_tokens,
"messages": [{"role": "user", "content": prompt}],
}
t0 = time.time()
resp = _post(f"{base}/v1/chat/completions", payload, timeout=300)
elapsed = time.time() - t0
msg = resp["choices"][0]["message"]
return {
"host": base,
"model": model,
"elapsed_s": round(elapsed, 1),
"content": msg.get("content", ""),
"reasoning": msg.get("reasoning", ""),
"completion_tokens": resp["usage"]["completion_tokens"],
"finish_reason": resp["choices"][0]["finish_reason"],
}
def run_embedding(base: str, model: str, text: str) -> dict:
t0 = time.time()
resp = _post(f"{base}/v1/embeddings", {"model": model, "input": text}, timeout=30)
elapsed = time.time() - t0
vec = resp["data"][0]["embedding"]
return {
"host": base,
"model": model,
"elapsed_s": round(elapsed, 2),
"dimensions": len(vec),
"sample": vec[:4],
}
def print_chat_result(result: dict) -> None:
content = result.get("content", "")
reasoning = result.get("reasoning", "")
print(f"\nTime: {result['elapsed_s']}s")
print(f"Tokens: {result['completion_tokens']} (finish: {result['finish_reason']})")
if reasoning:
print(f"Reasoning ({len(reasoning)} chars):\n{reasoning[:300]}{'...' if len(reasoning) > 300 else ''}")
print(f"Content ({len(content)} chars):\n{content}")
def print_embedding_result(result: dict) -> None:
print(f"\nTime: {result['elapsed_s']}s")
print(f"Dimensions: {result['dimensions']}")
print(f"Sample: {result['sample']}")
def base_argparser(description: str):
import argparse
p = argparse.ArgumentParser(description=description)
p.add_argument("host", help="Host short name (clementine|banana|cranberry|star) or URL")
p.add_argument("model", help="Model name (e.g. nemotron-3-nano:4b)")
p.add_argument("--skip-warmup", action="store_true", help="Skip model warm-up")
return pTest Runner (run_tests.py)
The runner orchestrates all test classes across all hosts. Each host runs a fully serial warm → test → warm → test sequence, while all hosts run their sequences in parallel with each other. I settled on this after running into request contention problems with a parallel warm-up approach — more on that in the methodology section.
#!/usr/bin/env python3
"""
Local LLM Benchmark Test Runner
================================
Runs all benchmark test classes against their assigned hosts and models.
Execution model:
- Each host runs a fully serial sequence: warm → test → warm → test → ...
- No concurrent requests are ever sent to the same host
- All hosts run their sequences in parallel with each other
- Results are averaged over N runs (default: 3)
Usage:
python run_tests.py # 3-run average, all tests
python run_tests.py --runs 5 # average over 5 runs
python run_tests.py --runs 1 # single run
python run_tests.py --host star # only star tests
python run_tests.py --id class4_coding # single test by ID
python run_tests.py --list # list all test IDs and exit
"""
import json
import os
import sys
import threading
import argparse
import concurrent.futures
from datetime import datetime
from collections import defaultdict
from test_utils import resolve_host, warm_model, print_chat_result, print_embedding_result
import class1_tools_fast
import class2_reasoning_fast
import class3_reasoning_slow
import class4_coding
import class5_research
import class6_vision
import class7_embedding
# ── Test case registry ────────────────────────────────────────────────────────
# Each entry maps an ID to a class module, host short name, and model.
# Tests within a host run top-to-bottom; hosts run in parallel.
TEST_CASES = [
# clementine — tools_fast failover (order:2) + embedding primary (order:1)
{"id": "class1_tools_fast_clementine", "module": class1_tools_fast, "host": "clementine", "model": "nemotron-3-nano:4b"},
{"id": "class7_embedding_clementine", "module": class7_embedding, "host": "clementine", "model": "embeddinggemma"},
# banana — tools_fast primary (order:1) + vision + embedding failover (order:2)
{"id": "class1_tools_fast_banana", "module": class1_tools_fast, "host": "banana", "model": "nemotron-3-nano:4b"},
{"id": "class6_vision_banana", "module": class6_vision, "host": "banana", "model": "qwen3.5:9b"},
{"id": "class7_embedding_banana", "module": class7_embedding, "host": "banana", "model": "embeddinggemma"},
# cranberry — reasoning_fast + reasoning_slow/tools_slow + coding
{"id": "class2_reasoning_fast", "module": class2_reasoning_fast, "host": "cranberry", "model": "gemma4:latest"},
{"id": "class3_reasoning_slow", "module": class3_reasoning_slow, "host": "cranberry", "model": "gemma4:26b"},
{"id": "class4_coding", "module": class4_coding, "host": "cranberry", "model": "qwen3.5:35b"},
# star — research only; dedicated to gpt-oss:120b with no other models loaded
{"id": "class5_research", "module": class5_research, "host": "star", "model": "gpt-oss:120b"},
]Results from each run are saved to a timestamped JSON file (results_YYYYMMDD_HHMMSS.json), averaging across all successful runs per test ID. Raw per-run data is preserved for variance analysis.
Test Cases
Each test class has its own script that can be run standalone against any host and model, or invoked by the runner. Warm-up is embedded in each script and skipped when the runner manages the sequence.
Class 1 — Tools Fast: Structured JSON Extraction
I wanted to test a model’s ability to follow strict output formatting and extract values correctly. The prompt includes intentional ambiguity — a month name alongside an explicit date — to catch models that interpret rather than extract.
Success criteria: Valid JSON with correct values; response < 10s
#!/usr/bin/env python3
"""
Class 1 - Tools Fast: Structured JSON extraction.
Tests a model's ability to extract structured data and return valid JSON.
Default: nemotron-3-nano:4b on clementine.
Usage:
python class1_tools_fast.py clementine nemotron-3-nano:4b
python class1_tools_fast.py banana gemma4:latest --skip-warmup
"""
from test_utils import resolve_host, warm_model, run_chat, print_chat_result, base_argparser
PROMPT = (
'Extract the following as JSON with keys name, date, total: '
'"Please process payment of $847.50 to Sarah Johnson by end of month, '
'November 30th 2026." Return only the JSON object, nothing else.'
)
SUCCESS_CRITERIA = "Valid JSON with correct values; response < 10s"
def run(base: str, model: str, skip_warmup: bool = False) -> dict:
if not skip_warmup:
warm_model(base, model)
return run_chat(base, model, PROMPT)
def main():
args = base_argparser("Class 1 – Tools Fast: structured JSON extraction").parse_args()
base = resolve_host(args.host)
result = run(base, args.model, skip_warmup=args.skip_warmup)
print_chat_result(result)
if __name__ == "__main__":
main()Class 2 — Reasoning Fast: Quick Factual Explanation
A concise, accurate response to a well-known technical concept. The three-sentence constraint filters models that pad output unnecessarily — a real inference cost when you’re running this at home lab scale.
Success criteria: Accurate and concise; response < 5s
#!/usr/bin/env python3
"""
Class 2 - Reasoning Fast: Quick factual explanation.
Tests concise, accurate responses to a well-known technical concept.
Default: gemma4:latest on banana or cranberry.
Usage:
python class2_reasoning_fast.py banana gemma4:latest
python class2_reasoning_fast.py cranberry gemma4:latest
"""
from test_utils import resolve_host, warm_model, run_chat, print_chat_result, base_argparser
PROMPT = "In 2-3 sentences, explain what a transformer neural network is."
SUCCESS_CRITERIA = "Accurate and concise; response < 5s"
def run(base: str, model: str, skip_warmup: bool = False) -> dict:
if not skip_warmup:
warm_model(base, model)
return run_chat(base, model, PROMPT)
def main():
args = base_argparser("Class 2 – Reasoning Fast: quick factual explanation").parse_args()
base = resolve_host(args.host)
result = run(base, args.model, skip_warmup=args.skip_warmup)
print_chat_result(result)
if __name__ == "__main__":
main()Class 3 — Reasoning Slow: Mid-Tier Research
Structured analysis and trade-off reasoning on a technical topic. I reuse the same prompt in Class 5 to get a direct quality comparison between mid-tier and research-grade models on identical input.
Success criteria: Structured comparison with clear trade-offs; response < 120s
#!/usr/bin/env python3
"""
Class 3 - Reasoning Slow: Mid-tier research comparison.
Tests structured analysis and trade-off reasoning on a technical topic.
Default: gemma4:26b on cranberry (ollama).
Usage:
python class3_reasoning_slow.py cranberry gemma4:26b
python class3_reasoning_slow.py star gemma4:26b
"""
from test_utils import resolve_host, warm_model, run_chat, print_chat_result, base_argparser
PROMPT = (
"Compare sparse vs dense retrieval methods for RAG systems. "
"What are the trade-offs and when should each be used?"
)
SUCCESS_CRITERIA = "Structured comparison with clear trade-offs; response < 120s"
def run(base: str, model: str, skip_warmup: bool = False) -> dict:
if not skip_warmup:
warm_model(base, model)
return run_chat(base, model, PROMPT)
def main():
args = base_argparser("Class 3 – Reasoning Slow: mid-tier research comparison").parse_args()
base = resolve_host(args.host)
result = run(base, args.model, skip_warmup=args.skip_warmup)
print_chat_result(result)
if __name__ == "__main__":
main()Class 4 — Coding: Async Python Code Generation
Code generation against specific requirements: async patterns, type hints, retry logic, and correct exponential backoff. A model that produces syntactically valid but logically wrong backoff — linear instead of exponential — fails this test.
Success criteria: Valid Python; uses asyncio/aiohttp; correct exponential backoff
#!/usr/bin/env python3
"""
Class 4 - Coding: Async Python code generation.
Tests code generation quality: correct async patterns, type hints, retry logic.
Default: qwen3.5:35b-a3b-coding-nvfp4 on star.
Usage:
python class4_coding.py star qwen3.5:35b-a3b-coding-nvfp4
python class4_coding.py star gpt-oss:120b
"""
from test_utils import resolve_host, warm_model, run_chat, print_chat_result, base_argparser
PROMPT = (
"Write a Python async function that fetches JSON from a URL with retry logic "
"(max 3 attempts, exponential backoff). Include type hints and a docstring."
)
SUCCESS_CRITERIA = "Valid Python; uses asyncio/aiohttp; correct exponential backoff"
def run(base: str, model: str, skip_warmup: bool = False) -> dict:
if not skip_warmup:
warm_model(base, model)
return run_chat(base, model, PROMPT)
def main():
args = base_argparser("Class 4 – Coding: async Python code generation").parse_args()
base = resolve_host(args.host)
result = run(base, args.model, skip_warmup=args.skip_warmup)
print_chat_result(result)
if __name__ == "__main__":
main()Class 5 — Research: Deep Synthesis
The same prompt as Class 3 — deliberately. Given the same question, I wanted to see how much more depth and structure a 120B research-grade model produces compared to a 26B mid-tier model. Content length and token count are the primary quality signals at this scale.
Success criteria: Deeper and more structured than Class 3 result; response < 180s
#!/usr/bin/env python3
"""
Class 5 - Research: Deep synthesis on a technical topic.
Same prompt as Class 3 (reasoning slow) — used to compare depth and structure
between mid-tier and research-grade models.
Default: gpt-oss:120b on star.
Usage:
python class5_research.py star gpt-oss:120b
python class5_research.py star qwen3.5:122b
"""
from test_utils import resolve_host, warm_model, run_chat, print_chat_result, base_argparser
PROMPT = (
"Compare sparse vs dense retrieval methods for RAG systems. "
"What are the trade-offs and when should each be used?"
)
SUCCESS_CRITERIA = "Deeper and more structured than Class 3 result; response < 180s"
def run(base: str, model: str, skip_warmup: bool = False) -> dict:
if not skip_warmup:
warm_model(base, model)
return run_chat(base, model, PROMPT)
def main():
args = base_argparser("Class 5 – Research: deep synthesis").parse_args()
base = resolve_host(args.host)
result = run(base, args.model, skip_warmup=args.skip_warmup)
print_chat_result(result)
if __name__ == "__main__":
main()Class 6 — Vision: Scene Understanding (Text Proxy)
Full vision benchmarking requires image input, which introduces too many variables for a repeatable benchmark. Instead, I use a descriptive generation task as a proxy: specificity of colour, lighting, and compositional detail is a reasonable stand-in for whether a model can interpret a scene. Generic answers fail regardless of response time.
Success criteria: Descriptive and evocative; specific colours and lighting detail; response < 15s
#!/usr/bin/env python3
"""
Class 6 - Vision: Scene understanding (text proxy).
Tests descriptive language generation as a proxy for vision quality.
Full vision testing requires image input; this evaluates baseline output quality.
Default: qwen3.5:9b on banana.
Usage:
python class6_vision.py banana qwen3.5:9b
python class6_vision.py banana gemma4:latest
"""
from test_utils import resolve_host, warm_model, run_chat, print_chat_result, base_argparser
PROMPT = (
"Describe what you would expect to see in a photograph taken at golden hour "
"of a rural farm in Virginia in autumn. What colours, lighting, and "
"compositional elements would be present?"
)
SUCCESS_CRITERIA = "Descriptive and evocative; specific colours and lighting detail; response < 15s"
def run(base: str, model: str, skip_warmup: bool = False) -> dict:
if not skip_warmup:
warm_model(base, model)
return run_chat(base, model, PROMPT)
def main():
args = base_argparser("Class 6 – Vision: scene understanding (text proxy)").parse_args()
base = resolve_host(args.host)
result = run(base, args.model, skip_warmup=args.skip_warmup)
print_chat_result(result)
if __name__ == "__main__":
main()Class 7 — Embedding: Vector Generation
Confirms the assigned model produces a valid embedding vector of the expected dimensionality. Latency is measured in the warm (resident) state — the first call loads the model and can be 10–20× slower, so all embedding results here reflect a pre-warmed model.
Success criteria: Valid embedding vector returned; response < 2s
#!/usr/bin/env python3
"""
Class 7 - Embedding: Vector generation.
Tests that the model produces a valid embedding vector of the expected dimensions.
Default: embeddinggemma on banana or clementine.
Usage:
python class7_embedding.py banana embeddinggemma
python class7_embedding.py clementine embeddinggemma
"""
from test_utils import resolve_host, warm_model, run_embedding, print_embedding_result, base_argparser
PROMPT = (
"Retrieval-Augmented Generation combines a retriever with a "
"generative model to produce grounded responses."
)
SUCCESS_CRITERIA = "Valid embedding vector returned; response < 2s"
def run(base: str, model: str, skip_warmup: bool = False) -> dict:
if not skip_warmup:
warm_model(base, model)
return run_embedding(base, model, PROMPT)
def main():
args = base_argparser("Class 7 – Embedding: vector generation").parse_args()
base = resolve_host(args.host)
result = run(base, args.model, skip_warmup=args.skip_warmup)
print_embedding_result(result)
if __name__ == "__main__":
main()Methodology
Warm-Up and the Cold-Load Problem
Ollama keeps models resident in memory for fast subsequent requests. When a request arrives for a model that isn’t loaded, Ollama cold-loads it — which takes 30 seconds to several minutes depending on model size. Every benchmark here is preceded by an explicit warm-up call that blocks until the model reports ready, so all measurements reflect the warm (resident) state.
I use /api/generate with keep_alive: -1 for chat models to keep them resident indefinitely. Embedding models reject that endpoint with HTTP 400, so those use /v1/embeddings instead.
Serial Per-Host, Parallel Across Hosts
My first attempt ran a parallel warm-up phase across all cranberry models — gemma4:latest, gemma4:26b, and qwen3.5:35b — simultaneously before each test batch. The result: request contention inflated subsequent timings significantly. Coding measured 44s averaged when the true serial baseline turned out to be 24.8s.
The fix was to embed warm-up directly into the per-host serial sequence:
for each host (in parallel with other hosts):
for each test on this host:
warm_model(host, model) ← blocks until ready
run_test(host, model) ← timed measurement
No concurrent requests are ever sent to the same host.
Averaging
I averaged all final results across 3 runs. Single-run benchmarks showed wide variance — a warm KV cache from a previous run could produce a 23s result where the true average was 25s. Raw per-run data is preserved in the results JSON for variance inspection.
python run_tests.py # 3-run average, all tests
python run_tests.py --runs 5 # custom run count
python run_tests.py --host star --id class5_research # targeted runMetrics Collected
| Metric | Description |
|---|---|
| Avg response time | Mean wall-clock seconds across all runs |
| Avg output tokens | Mean completion tokens across all runs |
| Avg content length | Mean characters in content field |
| Reasoning length | Characters in reasoning field (internal chain-of-thought) |
| Finish reason | stop = completed naturally; length = hit token limit |
Standard parameters across all chat tests: max_tokens: 8192, default temperature, OpenAI-compatible /v1/chat/completions.
Picking the Research Model
The research class was the hardest to assign — it needed the best available model, and star was the only host with enough memory for it. I tested six candidates using the same RAG-comparison prompt as Class 3, with warm-up applied before each run:
| Model | Size | Quant | Response Time | Content (chars) | Reasoning (chars) | Tokens | Finish |
|---|---|---|---|---|---|---|---|
gemma4:26b | 18.0 GB | Q4_K_M | 39s | 5,551 | 2,674 | 1,941 | stop |
gemma4:31b | 19.9 GB | Q4_K_M | 1m 36s | 5,486 | 2,071 | 1,791 | stop |
deepseek-r1:70b | 43.0 GB | Q4_K_M | 2m 08s | 3,050 | 3,866 | 1,311 | stop |
qwen3.5:122b | 81.4 GB | Q4_K_M | 2m 16s | 7,238 | 4,057 | 2,729 | stop |
gpt-oss:120b | 65.4 GB | MXFP4 | 1m 11s | 17,896 | 673 | 4,727 | stop |
devstral-2:123b | 74.9 GB | Q4_K_M | — | — | — | — | TIMEOUT |
Two models were immediately eliminated:
devstral-2:123b: Loaded 81 GB into memory then failed to respond to any prompt at 5-minute and 10-minute timeouts. Not usable.qwen3.5:122b: Requires a/no_thinkprefix ormax_tokens > 8192. Without it, the reasoning chain consumes the entire token budget before generating any content.
gpt-oss:120b was the clear winner. The MXFP4 quantisation gives 120B parameters at 65 GB, producing 3× more content than the Gemma models at a faster wall-clock time. The 4% reasoning overhead (673 chars) vs deepseek-r1:70b’s 56% (3,866 chars) means nearly all output is usable content rather than internal chain-of-thought.
Reasoning Overhead Compared
| Model | Reasoning % of total output |
|---|---|
deepseek-r1:70b | 56% — built for correctness, not volume |
qwen3.5:122b | 36% |
gemma4:26b | 33% |
gemma4:31b | 29% |
gpt-oss:120b | 4% — almost entirely usable content |
Fixing the Memory Overcommits
With model selections made, I audited the existing LiteLLM configuration against the hardware. Two hosts had memory overcommits that were causing model swapping on every affected request.
banana — VRAM Overcommit
The original assignment placed gemma4:latest (~10.8 GB loaded) alongside qwen3.5:9b (~7.5 GB) on banana’s 16 GB VRAM. Together they exceeded the usable ~14 GB, so Ollama was evicting gemma4:latest on every vision request and reloading it for the next reasoning request — a 30–60s penalty each way, which I could see directly in the 53s vision latency.
The fix was to replace gemma4:latest with nemotron-3-nano:4b (~3 GB) on banana. CUDA acceleration means nemotron-3-nano:4b runs at 1.3s on the 4070Ti vs 5.3s on clementine’s M4 Pro — so banana actually became the better tools_fast primary, not a worse one. The new memory profile (3 GB + 7.5 GB + 0.7 GB = 11.2 GB) fits cleanly within 14 GB, and vision latency dropped from 53s to 26.5s as a direct result.
star — Unified Memory Overcommit
The original config assigned both gpt-oss:120b (65 GB) and qwen3.5:35b-a3b-coding-nvfp4 (22 GB) to star. Combined they hit 87 GB against ~84 GB available, meaning any coding request following a research request would trigger a full model swap — adding 45–60s of cold-load latency.
I moved coding to cranberry instead. qwen3.5:35b (standard quantisation) was already installed there, and benchmarks showed 24.8s averaged — acceptable for a coding task. The nvfp4 variant on star measured 10.4s, which is faster, but not worth the swap penalty on every research request. star is now dedicated entirely to gpt-oss:120b with no eviction risk.
Cranberry memory check after the change: gemma4:latest (~10 GB) + gemma4:26b (~20 GB) + qwen3.5:35b (~24 GB) = ~44 GB against ~44 GB usable. Fully utilised, but all three models coexist without eviction.
Configuration Audit
Beyond the memory overcommits, I found four more problems in the LiteLLM configuration.
Wrong routing strategy. The config used simple-shuffle, which picks hosts at random and ignores the order field entirely. With order set to prioritise Apple Silicon for energy efficiency, about half of requests were going to the slower host. I switched to latency-based-routing, which respects order and routes to the lowest-latency available host.
Wrong provider prefix for embeddings. Both embeddinggemma entries used ollama_chat/embeddinggemma. The ollama_chat/ prefix routes to /v1/chat/completions; embedding models need ollama/ to reach /v1/embeddings. Every embedding request was going to the wrong endpoint.
Smart routers unreachable. reasoning-smart-router and tools-smart-router were defined in model_list but absent from model_group_alias. Clients using those alias names would get a 404 with no indication of why.
Fallback chains lacked host diversity. The original chain reasoning_fast → reasoning_slow → coding resolves entirely to cranberry. A cranberry outage would cascade through every fallback with no escape to another host. I added cross-host escapes: reasoning_fast can now fall to tools_fast (banana/clementine), and research gained → reasoning_slow → coding as a degraded-but-functional path when star is unavailable.
Results
Final Benchmark — Averaged Results (3 Runs)
| ID | Host | Model | Avg Time | Avg Tokens | Avg Content |
|---|---|---|---|---|---|
| class1_tools_fast_banana | banana | nemotron-3-nano:4b | 1.3s | 187 | 74c |
| class1_tools_fast_clementine | clementine | nemotron-3-nano:4b | 5.3s | 218 | 74c |
| class2_reasoning_fast | cranberry | gemma4:latest | 9.0s | 410 | 605c |
| class3_reasoning_slow | cranberry | gemma4:26b | 46.3s | 1,912 | 5,398c |
| class4_coding | cranberry | qwen3.5:35b | 24.8s | 911 | 3,270c |
| class5_research | star | gpt-oss:120b | 81.0s | 5,294 | 19,606c |
| class6_vision_banana | banana | qwen3.5:9b | 26.5s | 2,181 | 4,650c |
| class7_embedding_banana | banana | embeddinggemma | 0.10s | — | 768d |
| class7_embedding_clementine | clementine | embeddinggemma | 0.11s | — | 768d |
Response Time
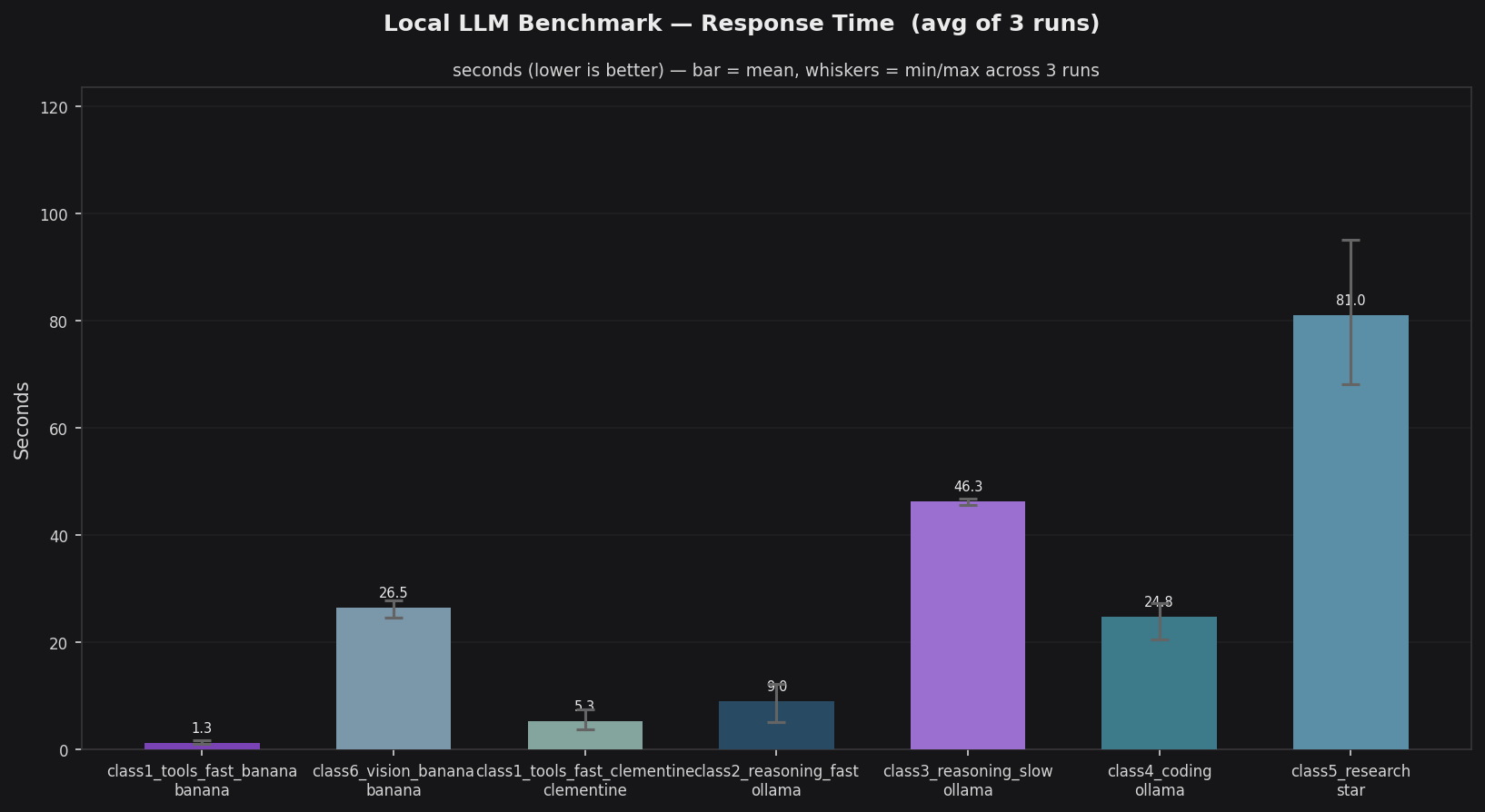
Response times span four orders of magnitude across the seven classes. nemotron-3-nano:4b on banana is the fastest chat model at 1.3s — CUDA acceleration gives it a 4× edge over the same model on clementine’s M4 Pro (5.3s). The three cranberry models cluster in the 9–46s band: gemma4:latest at 9.0s for fast reasoning, qwen3.5:35b at 24.8s for coding, and gemma4:26b at 46.3s for deep reasoning. gpt-oss:120b on star takes 81.0s but is justified by its output quality. Error bars (min/max across 3 runs) are narrow for all models, confirming stable, repeatable latency once models are fully warmed.
Content Length
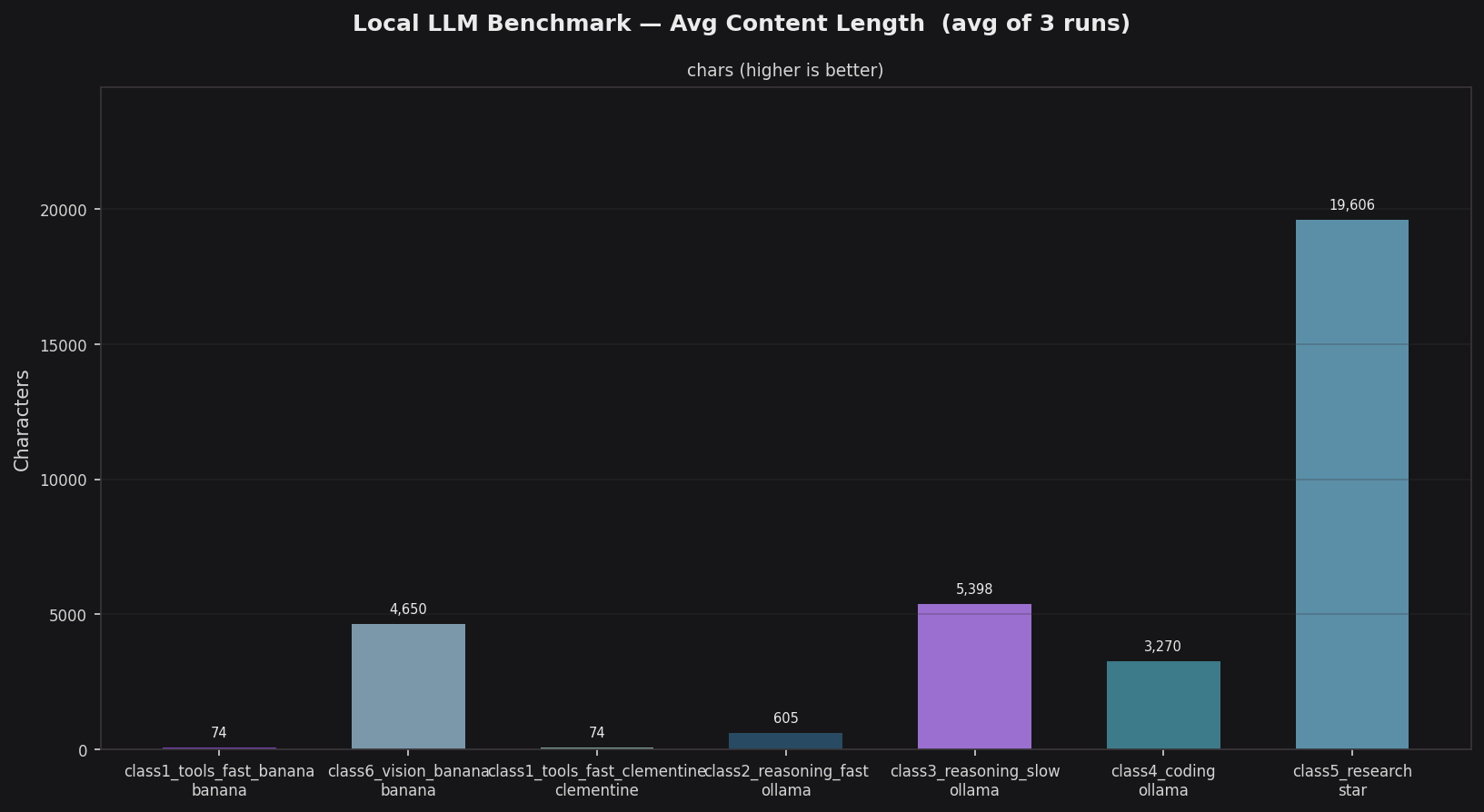
gpt-oss:120b dominates content output at 19,606 characters — more than 3.6× the next model (gemma4:26b at 5,398c) and over 260× the tools-fast model. This gap reflects both the model’s scale and its low reasoning overhead (only 4% of total output is internal chain-of-thought). qwen3.5:9b (vision, 4,650c) and qwen3.5:35b (coding, 3,270c) sit in the mid tier. nemotron-3-nano:4b’s 74c output is intentional — structured JSON extraction requires brevity, not depth.
Output Tokens
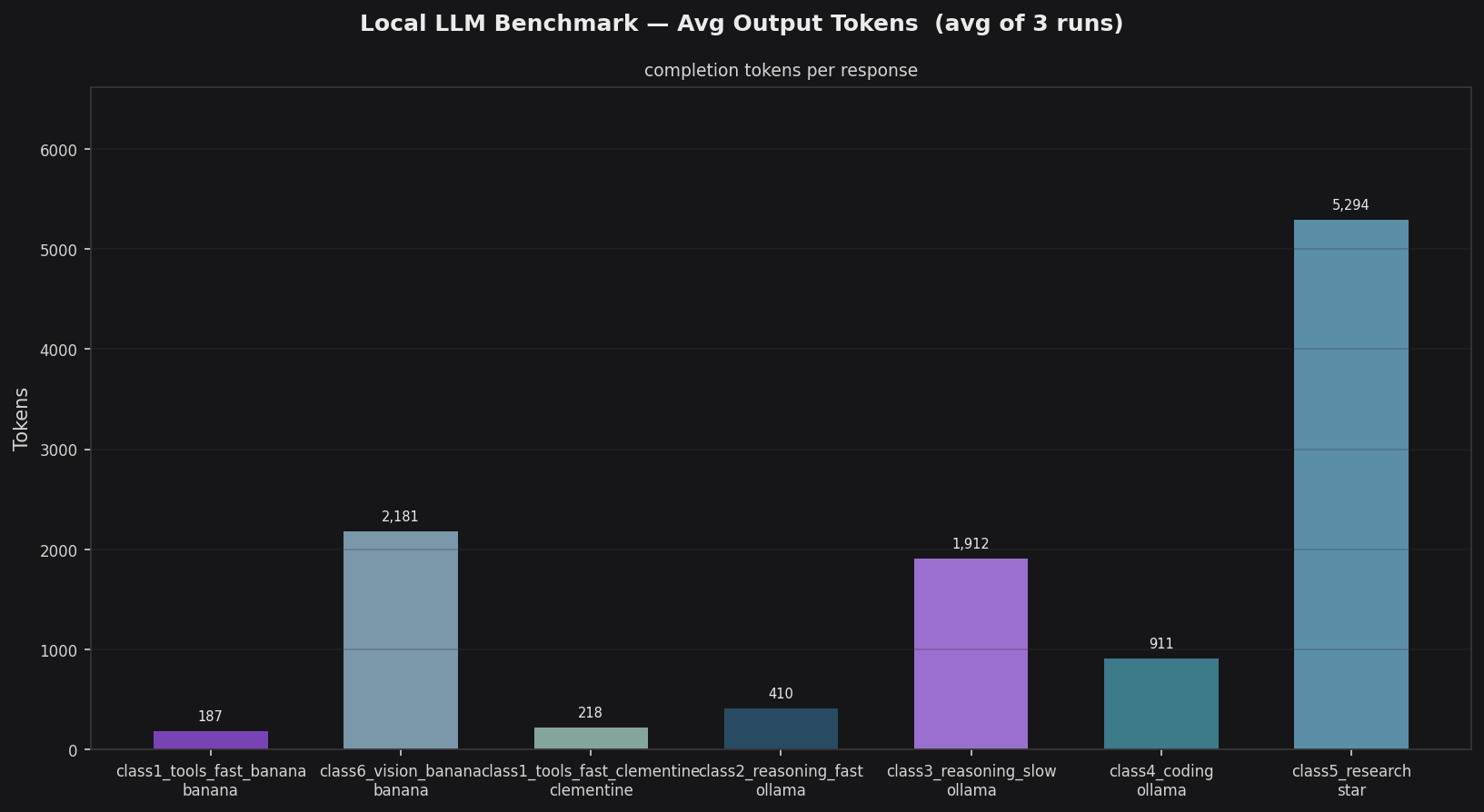
Token counts follow the same hierarchy as content length. gpt-oss:120b generates 5,294 tokens on average — nearly 3× the next model (gemma4:26b at 1,912). gemma4:latest produces only 410 tokens for the quick factual class, which is appropriate given its 2–3 sentence success criterion. nemotron-3-nano:4b averages 187–218 tokens; the slight variation between banana and clementine reflects minor non-determinism at default temperature.
Reasoning vs Content
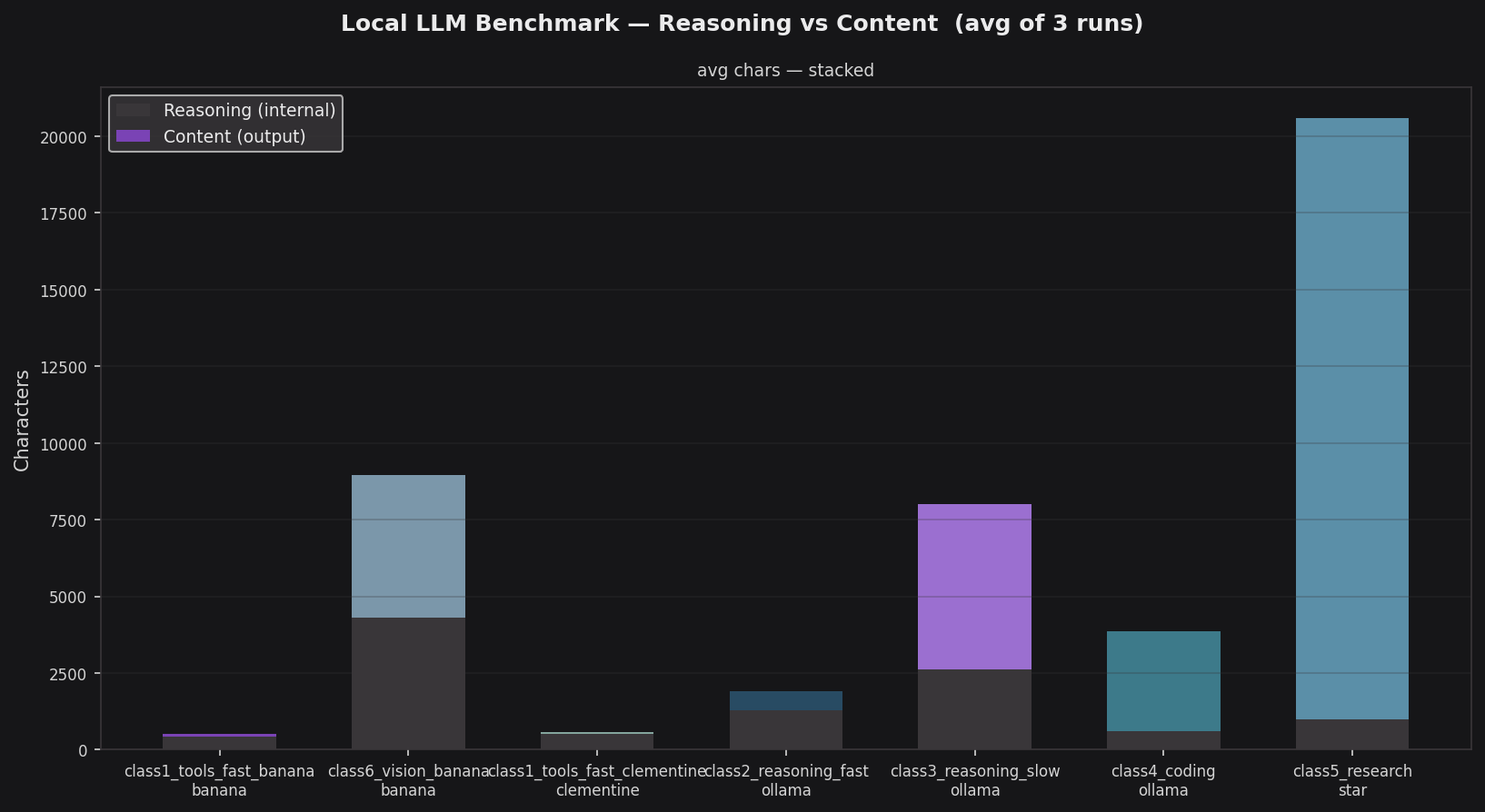
The stacked chart separates internal chain-of-thought (grey) from visible content output (coloured). gpt-oss:120b is the clear outlier — almost the entire bar is content, with only 673 reasoning characters against 19,606 of output (4% overhead). Everything else carries more reasoning than you might expect.
The two Qwen models show the highest overhead in the final configuration: qwen3.5:9b (vision) produces roughly as many reasoning characters as content characters (~48% overhead), and qwen3.5:35b (coding) is similar at ~42%. gemma4:latest (reasoning_fast) also has a disproportionately large grey section given its short 605-character output. nemotron-3-nano:4b is the only model with genuinely minimal reasoning, which makes sense for a structured extraction task.
The practical takeaway: for tasks where you’re paying per token or optimising for latency, the reasoning overhead of Qwen and Gemma models is worth accounting for. gpt-oss:120b is the exception — it produces dramatically more usable content per token than any other model tested, which is what made it the clear choice for the research tier.
Embedding Timing Note
Early single-run measurements showed clementine at 0.72s and banana at 2.57s — which looked like a real difference. Both figures included cold-load time. With proper warm-up applied, both hosts measure at ~0.1s. The gap disappears entirely once the model is resident; I kept clementine as primary as a tie-breaker for resilience, not latency.
Final Router Configuration
The validated alias-to-model-to-host mapping:
| Alias | Model | Primary Host | Avg Latency | Failover |
|---|---|---|---|---|
tools_fast | nemotron-3-nano:4b | banana | 1.3s | clementine |
tools_slow | gemma4:26b | cranberry | 46.3s | coding |
reasoning_fast | gemma4:latest | cranberry | 9.0s | tools_fast |
reasoning_slow | gemma4:26b | cranberry | 46.3s | coding |
coding | qwen3.5:35b | cranberry | 24.8s | reasoning_slow |
research | gpt-oss:120b | star | 81.0s | reasoning_slow |
vision | qwen3.5:9b | banana | 26.5s | — |
embedding | embeddinggemma | clementine | 0.11s | banana |
Fallback Chains
reasoning_fast → reasoning_slow → tools_fast → coding
reasoning_slow → tools_slow → coding
tools_fast → tools_slow → reasoning_fast → coding
tools_slow → reasoning_slow → coding
coding → reasoning_slow → tools_slow
research → reasoning_slow → coding
Cross-host escapes are intentional: reasoning_fast can fall to tools_fast (banana/clementine) so a cranberry outage doesn’t strand the entire reasoning chain.
Conclusion
Going through this process surfaced four meaningful problems in the initial LiteLLM configuration: two memory overcommits causing model swapping on every affected request, a routing strategy that ignored the priority ordering, an incorrect embedding provider prefix, and fallback chains with no resilience to a single-host failure.
The most impactful single change was replacing gemma4:latest with nemotron-3-nano:4b on banana. It fixed the VRAM overcommit, moved tools_fast primary to the faster CUDA host (1.3s vs 5.3s), and cut vision latency in half — three problems resolved by one model reassignment.
Open-source models are improving fast, and the landscape will look different by the time new 26B and 120B candidates are released. When that happens, I’ll run through this same process again to see if the assignments still hold.